Home > Kryptographie > Einweg-Hashfunktionen
Kryptographie
Was hat es denn nun mit diesen seltsamen Hash-Funktionen auf sich, die Sie vermutlich schon öfter in einigen Kapiteln bemerkt haben, und warum sind Sie von so großer Bedeutung in der Kryptographie?
Zunächst ein paar grundlegende Informationen. Eine Einweg-Hashfunktion H(M) verarbeitet eine beliebig lange Nachricht M. Die Funktion erzeugt einen Hashwert h fester Länge (z. B. 128, 160, 192 oder 256 Bit). Das Besondere an dieser Funktionen ist die Schwierigkeit, ein M, d. h. eine Nachricht, aus dem Hashwert h zu berechnen. Anders ausgedrückt bedeutet das: Es ist schwer, zu gegebenem h ein M mit H(M) = h zu berechnen. Des Weiteren sollte es eines großen Rechenaufwands bedürfen, zu einer gegebenen Nachricht M eine andere Nachricht M' zu berechnen mit H(M) = H(M'). Genau diese Eigenschaften machen Einweg-Hashfunktionen für die Kryptographie so interessant.
Grundlagen von Hashfunktionen sind ausgeklügelte sog. Kompressions-Funktionen, welche die Daten auf einen bestimmten Hashwert reduzieren, dabei aber alle Daten eines Blocks berücksichtigen (von "echter", im Sinne von "verlustfreier" Kompression kann natürlich keine Rede sein). Mit bestimmten Rechenvorschriften werden die Datenwörter kräftig durchgemischt, so dass es praktisch unmöglich ist vorherzusagen, wie sich die Änderung auch nur eines einzigen Nachrichtenbits auf das Ergebnis auswirken wird.
So sieht beispielsweise die Kompressions-Funktion des Hash-Algorithmus MD5 (siehe Algorithmen) aus:
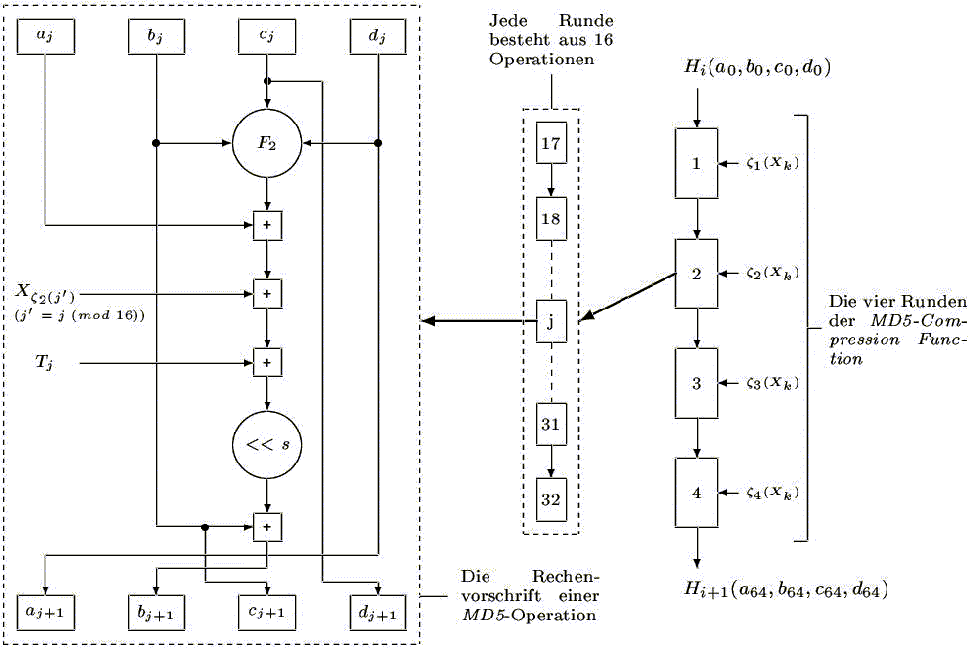
Quelle: Linux-Magazin
![]()
![]()
Stellen wir uns folgende Situation vor: Die Person A – nennen wir sie traditionsgemäß Alice – möchte ein Programm für andere Personen – sagen wir Bob – unzugänglich machen. Also baut sie – die einfachste Lösung – einen Passwortschutz ein. Das Problem: Um das Passwort überprüfen zu können, muss es das Programm auf der Festplatte in einer separaten Datei speichern. Nehmen wir an, Bob ist ebenfalls ein Benutzer dieses Computers. Da er an der Nutzung von Alices Programm interessiert ist, dauert es nicht lange, bis er herausfindet, wo das Passwort gespeichert wird. Er öffnet die Datei, um sich des Passwortes zu bemächtigen. Eine einfache Lösung dieses Problems wäre: Das Programm speichert nicht etwa das Passwort selbst, sondern nur dessen Hashwert h. Es berechnet also hP = H(P). Bob kann zwar nach wie vor den Inhalt der Datei auslesen, kennt das Passwort jedoch nicht. Es stellt für ihn eine zu große Schwierigkeit dar, ein Passwort mit demselben Hashwert zu berechnen. Hinweis: Das sind natürlich nicht Bobs einzige Möglichkeiten. Er kann den Hashwert manipulieren, indem er den Hashwert seines eigenen Passwortes einfügt; auch könnte er den Hashwert ganz löschen. Aber das ist eine andere Sache, die wir hier geflissentlich übergehen wollen.
In den meisten Krypto-Programmen kommen Hash-Algorithmen zum Einsatz, um das Passwort zu überprüfen. Aber mit Hashfunktionen kann man noch viel mehr machen. Sie können z. B. den Hashwert eines Passworts als Schlüssel für einen Verschlüsselungs-Algorithmus benutzen. Tatsächlich erweist sich eine gute Einweg-Hashfunktionen als "eierlegende Wollmilchsau" in der Kryptographie – schauen Sie sich nur an, was diese Funktionen alles für Sie leisten können:
Unglücklicherweise gibt es hierbei ein Problem (wie könnte es anders sein?), das ich im Folgenden erläutern möchte.
![]()
![]()
Der Angreifer hat noch ein As im Ärmel: Er hat sich insgeheim eine Art Datenbank angelegt, in der eine Reihe möglicher Passwörter gespeichert ist – samt Hashwerten. Er vergleicht also den Hash, der, sagen wir, in einer verschlüsselten Datei zwecks Passwort-Überprüfung gespeichert ist, mit denen in seiner Datenbank und kann somit, wenn er Glück hat, das zugehörige Passwort lokalisieren. Die Chancen stehen nicht schlecht (wenn das Passwort schlecht gewählt und die Datenbank des Angreifers groß genug ist), dass er diese Datei erfolgreich entschlüsseln kann. Denn leider haben Menschen einen Hang zu schlechten Passwörtern. So einen fiesen Angriff nennt man Dictionary Attack oder Wörterbuch-Angriff. Das Übelste an der Sache ist nicht unbedingt, dass der Angreifer die Datei entschlüsseln kann, sondern der Umstand, dass er nun das Passwort kennt und möglicherweise noch mehr schlimme Sachen damit anrichten kann – stellen Sie sich nur vor, dass Alice das Passwort noch für ganz andere Zwecke benutzt! Merken Sie sich daher: Benutzen Sie nicht dasselbe Passwort in unterschiedlichen Szenarien und Wechseln Sie Ihre Passwörter regelmäßig! Um sich nicht reihenweise komplizierte Passwörter merken zu müssen, sollten Sie die Sicherheit des Passwortes nach dem Sicherheitsniveau des Szenarios wählen. Ist Ihr Chat-Passwort so wichtig wie Ihr Passwort für Ihren Internet-Zugang? Setzen Sie Ihre Prioritäten – oder schaffen Sie sich einen Passwort-Safe an, in dem Sie all Ihre Passwörter mit Hilfe eines Master-Passwortes speichern. – Sorry, ich schweife ab; mehr Informationen zum Thema finden Sie im Kapitel über die Schlüssellänge (siehe speziell die Schlussbemerkung) sowie im Passwort-How-To.
Alice gibt sich jedoch nicht geschlagen – es muss doch eine Lösung für dieses Problem geben! Und tatsächlich: Es gibt sie! Hier kommt wieder das berüchtigte Salt zum Einsatz, das wir bereits im Abschnitt über RC4 kennen gelernt haben. Und so ist es uns diesmal dienlich: Wir lassen uns eine (Pseudo-)Zufallssequenz generieren, sagen wir 10 Bytes (80 Bits). Wir hängen das Passwort an diese Sequenz und erzeugen den Hashwert. Dann speichern wir sowohl die Zufallssequenz als auch den Hashwert. Beim Überprüfen des Passwortes wird dieser Vorgang wiederholt und die Resultate verglichen. Der Angreifer kann zwar das Salt auslesen, gewinnt dadurch aber rein gar nichts – im Gegenteil: Ein Wörterbuch-Angriff ist jetzt nicht mehr möglich. Wenn er eine derartige Datenbank einrichten wollte, müsste er auch sämtliche Möglichkeiten für das Salt berücksichtigen. Dazu braucht er sage und schreibe 280 (ca. 1024) Wörterbücher. Auf der ganzen Welt gibt es aber nicht genug Speicherplatz, um diese Menge an Daten festzuhalten. Dieses äußerst nützliche Verfahren sollte wenn möglich immer angewandt werden, da es wenig Zeit kostet und viel Sicherheit bietet.
![]()
![]()
Bei bestimmten Anwendungen gibt es noch ein zweites Problem, von dem ich bisher nichts erwähnt habe: Manchmal genügt die Einweg-Eigenschaft nicht, vielmehr braucht man zusätzlich noch die sog. Kollisionsresistenz. Das bedeutet, dass es schwer sein soll, zwei beliebige Nachrichten M und M' zu finden, die denselben Hashwert h liefern. Dagegen gibt es jedoch – zum Leidwesen der Krypto-Freunde – einen Angriff, der sich Geburtstags-Angriff nennt. Der etwas ungewöhnliche Name rührt von einem Paradoxon aus der Statistik her, dem sog. Geburtstags-Paradoxon: Auf einer Geburtstagsparty befinden sich n Personen. Die Wahrscheinlichkeit, dass eine der Personen am selben Tag wie der Gastgeber Geburtstag hat, beträgt
p = 1 − (364/365)n
Das bedeutet logischerweise: Je mehr Personen die Party bevölkern, desto höher ist die Wahrscheinlichkeit. Wie viele Leute müssen sich auf der Party aufhalten, damit die Wahrscheinlichkeit größer als 50 Prozent ist? Die Antwort lässt sich berechnen:
(364/365)n > 0,5
n > log364/3650,5
n > ~252,65
Demnach sind also 253 Personen nötig. Wie groß ist aber die Wahrscheinlichkeit, dass die Geburtstage zweier Gäste zufällig übereinstimmen? Die Berechnung ist schon etwas komplizierter:
p = 1 − 365! / ((365 − n) · 365n)
In diesem Fall reichen schon 23 Personen aus, damit die Wahrscheinlichkeit größer als 50 Prozent ist! Der Umstand für diese recht große Differenz liegt darin begründet, dass die Anzahl möglicher Gästepaare quadratisch, die Anzahl potenzieller Übereinstimmungen mit dem Gastgeber dagegen nur linear anwächst.
Diese in der Tat paradoxe Erscheinung lässt sich, wie sofort auffällt, auch auf Hashfunktionen übertragen. Die Anzahl der Tage eines Jahres entspricht dann der aller möglichen 2m Hashwerte, die Gesamtzahl n aller Gäste zur Anzahl der Nachrichten, die erforderlich sind, um eine bestimmte Wahrscheinlichkeit für eine Übereinstimmung zu erreichen. Eine Näherung für die 50/50-Chance bei einer Hashfunktion ist
n = 1,2 · 2m/2
Eine Hashfunktion erzeugt eine m-Bit-Ausgabe. Um eine Nachricht zu finden, die einen bestimmten Hashwert ergibt (vgl. analog dazu: Übereinstimmungen mit dem Gastgeber), muss die Funktion auf 2m Nachrichten angewendet werden. Aber: Um zwei Nachrichten zu finden, die denselben Hashwert ergeben (vgl. Anzahl möglicher Gästepaare), sind lediglich ca. 1,2 · 2m/2 Nachrichten erforderlich. Das ist ein großer Unterschied! Während der erste Angriff bei einer 128-Bit-Hashfunktion nach heutigem Stand der Technik undurchführbar ist, stellt der zweite bereits eine überwindbare Hürde da; es wären "nur" noch schätzungsweise "lächerliche" 264 Berechnungen nötig ...
(Teilweise zitiert nach: Bosau, Klaus: Tripwire – eine Ortsbestimmung, Teil 3. Siehe Artikel im Linux-Magazin.)
![]()
![]()
Die meisten bekannten Algorithmen erzeugen einen Hashwert der Länge 128 oder 160, die moderneren sogar 256 Bit. MD5 z. B., der von Ronald L. Rivest entwickelt wurde, verarbeitet Nachrichtenblöcke der Länge 512 Bit. Wenn eine Nachricht kürzer ist, wird sie mit binären Nullen aufgefüllt. Nach diversen Funktionen wird ein 128-Bit-Hashwert ausgegeben. Es gibt einen Angriff, der mit Hilfe der Kompressions-Funktion Kollisionen produziert. Obwohl dieser die Sicherheit des Algorithmus im praktischen Einsatz nicht beeinträchtigt, wird allgemeinhin von der Nutzung MD5s eher abgeraten – man bevorzugt stattdessen SHA-1 (Secure Hash Algorithm), einen Algorithmus, der von der NSA (National Security Agency der USA) entwickelt wurde. Er ist MD5 sehr ähnlich, erzeugt jedoch Hashwerte der Länge 160 Bit und gilt als sicherer, da ihm neue, die Sicherheit erhöhende Funktionen hinzugefügt wurden. Wenn Sie irgendwann einmal eine Einweg-Hashfunktion brauchen sollten, kann ich Ihnen mit gutem Gewissen SHA empfehlen. Es sei denn, der Algorithmus ist bis dahin geknackt ... ;-) Sicher scheint auch der RIPE-MD-Algorithmus zu sein, der für die Europäische Union entwickelt wurde. Er erzeugt Hashwerte der Länge 128, 160, 192 oder 256 Bit. Ebenfalls die Erwähnung wert ist der von Eli Biham (der große Kryptoanalytiker) und Ross Anderson entworfene Tiger-Algorithmus, welcher auf Basis von 64-Bit-Wörtern (und nicht der üblichen 32 Bit) arbeitet, daher einen Geschwindigkeits-Vorteil gegenüber "älteren" Verfahren besitzt.
Auch Verschlüsselungs-Algorithmen können als Hashfunktionen eingesetzt werden; das Verfahren muss jedoch strengen Kriterien genügen, ansonsten sind Angriffe möglich, die beim Einsatz als normale Verschlüsselungs-Funktion nicht von Belang wären. Die Länge des Hashwertes entspricht dabei der Blocklänge des Algorithmus; von daher kommen nur solche Chiffrierungen in Betracht, die mit Blöcken einer Länge von mindestens 128 Bit arbeiten – 64-Bit reichten heute beileibe nicht mehr aus. Sofern verfügbar, sind Hash-Algorithmen wie MD5 oder besser SHA-1 aufgrund ihres zweckdienlicheren Designs vorzuziehen.
Ebenso können Einweg-Hashfunktionen als Verschlüsselungs-Verfahren, d. h. als Blockchiffrierung, eingesetzt werden. Eine Möglichkeit besteht darin, den vorherigen Chiffretextblock mit dem Schlüssel zu konkatenieren, die Hashfunktion darauf anzuwenden und den Hashwert mit dem aktuellen Klartextblock zu verschlüsseln:
Ci = Pi xor H(K, Ci − 1)
Pi = Ci xor H(K, Ci − 1)
Die Blocklänge ist hierbei die Länge des Ausgabewertes der Hashfunktion. Die Sicherheit des Verfahrens hängt von der Sicherheit der Hashfunktion ab. Algorithmen dieser Art werden sehr selten zur Verschlüsselung verwendet, da Hashfunktionen im Allgemeinen sehr langsam sind; Luby-Rackoff, eine weiterer Krypto-Algorithmus auf Basis einer Einweg-Hashfunktion, ist (unter Verwendung von SHA-1) im Schnitt nur ein Drittel mal so schnell wie der – im Vergleich zu neueren Verfahren extrem langsame – DES; Blowfish mit 16 Runden ist fast 3,9-mal so schnell wie DES und ca. 12,3-mal so schnell wie Luby-Rackoff.
| nach oben |
Weiter |
Letzte Änderung: 25.03.2002
© 2002 by Christian Thöing